Data relating to individuals in images – a risk in your unstructured data?
Do you store information of individuals in scanned images (e.g. driving license, passport) and is there a risk of this information not being genuinely protected? By default, this is an acceptable method to store data, but is the information really protected as well as it should be? How to be sure and how to identify possible risks in your unstructured data environment?
The challenge: We have been doing Dark Data Assessment since 2016, and from time to time we have faced situations where it would have been useful to know the potential risks of images. Challenging files may quite possibly account for over 8% of all of your data. In the case of terabytes or millions of files, it can be a taunting task to track down challenging content. How to identify images in large scale or from millions of files, which contain patterns relating to personal information (which is under EU GDPR or other regulations or guidelines)? Let’s look at an example.
On the left, we have a Finnish driving license, which also contains the social security number of the individual. On the right, we have a sample of the new Irish passport.
So, let’s take under consideration a typical large or medium-sized enterprise, having millions of files in the fileserver, intranet and emails. Are all those files protected? Is there a possibility, that there is data containing personal information that is stored in the wrong place? The answer almost certainly is yes. Since we started our assessment service, we have basically every single time found data that is in risk. How can we identify these files? Simply, we run our assessment service and identify the risks in the particular environment. Typically, most worrying targets are file servers and intranet servers, as they hold most of the data and are basically unstructured. We are now talking about that infamous M: disk and that shared folder labelled “common”.
Our assessment starts by carefully defining the scope and patterns to use. Then we scan the metadata and content. To content scanning we can also include optical character recognition (OCR) and examine the found data.
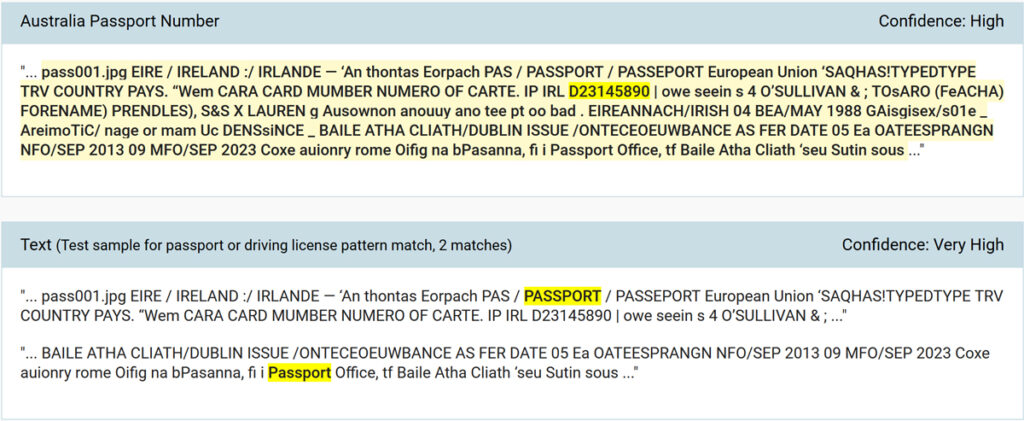
Regarding the images above, standard assessment would find and pinpoint them like this:
As we can see from the sample image of scanning results, in doing OCR for images, the quality of the image is important. While this might not be a 100% accurate method, manual search of images would be significantly less so.
Our standardized assessment, Dark Data Assessment – DDA 4D can help you with finding and securing your image files. Ask for more information on how to identify possible risk areas in your unstructured data environment and lower risks! Keep in mind, that DDA 4D moreover offers other benefits such as saving storage and backup capacity.
Keep your data safe – Order Dark Data Assessment now!
Unstructured data is growing rapidly, and without a clear governance strategy, organisations risk being overwhelmed by outdated, unmanaged, and potentially