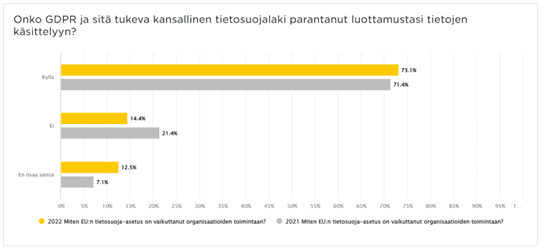
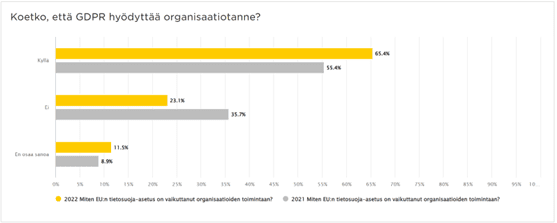
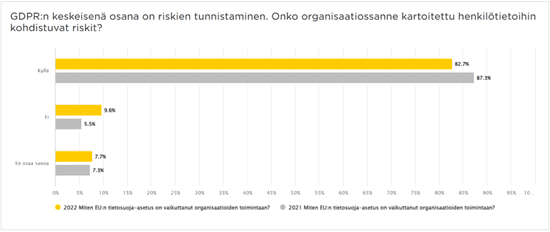
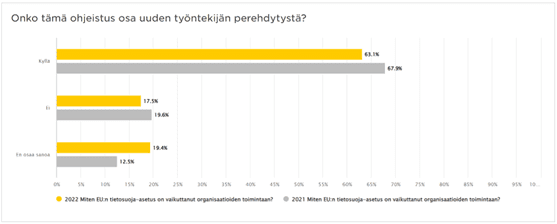
Viimeisimmät muutokset tietosuoja- ja tietoturvakentällä. Pysy ajan tasalla!

Tietosuojatyössä on tärkeää huomioida laaja-alaiset näkökulmat, jotta organisaatiossa voidaan varmistaa kattava ja tehokas tietosuoja. GDPR Tech on aina pitänyt tämän periaatteen ohjenuoranaan ja jatkaa samalla linjalla, koska tavoitteenamme on auttaa sinua onnistumaan tietosuojatyössäsi. Usein huomaamme tilanteita, joissa tietosuojaan panostetaan syvällisesti, esimerkiksi rekisteriselosteiden laatimisessa, mutta samalla unohdetaan ymmärrettävästi tiedottaminen tietosuojaan liittyvistä asioista. Helppotajuinen ja kansankielinen viestintä on tärkeää, jotta kaikki asianosaiset ymmärtävät tietosuojan merkityksen ja konkreettiset toimenpiteet.
Hyviä esimerkkejä onnistuneesta viestinnästä tietosuojasta ovat selkeät videot ja ”usein kysytyt kysymykset” -formaatti, joita hyödynnämme asiakkaidemme kanssa. Erään asiakkaamme kanssa olemme yhdistäneet useita erilaisia tietosuojaselosteita kahdeksi ymmärrettäväksi tiedotukseksi heidän verkkosivuillaan.
Uusi hallitus, uudet tavoitteet – Mitä se tarkoittaa tietosuojalle?
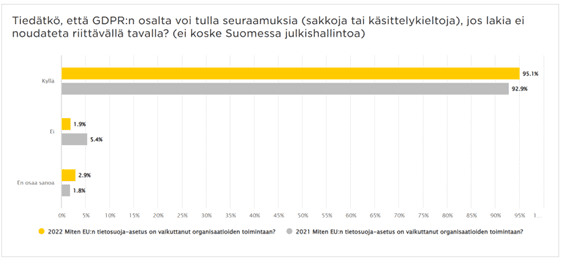
Paljon on tapahtunut viimeisimmän blogikirjoituksemme jälkeen. Suomi on saanut uuden hallituksen, joka asettaa uusia tavoitteita, kuten ”tietosuojalainsäädännön kokonaisuudistuksen”. Yhtenä osana hallinnolliset sakot laajennetaan koskemaan myös julkista sektoria. Hallitusohjelmaan on sisällytetty myös painotuksia tekoälyn osalta. Oletko jo antanut ohjeistusta organisaatiollesi koskien tekoälyn käyttöä? Tekoälyyn liittyen on jo nimittäin tapahtunut tietosuojan sekä tietoturvan poikkeamia, esimerkiksi matkapuhelinvalmistajan työntekijät olivat ladanneet suosittuun ChatGPT:hen aineistoa, jota olisi pitänyt käsitellä erittäin luottamuksellisesti.
Schrems II: Mitä seuraavaksi? Keskustelu jatkuu!
Kolmas vuosi Schrems II -keskustelua on käynnissä, ja kysymys kuuluu, pitäisikö vielä tehdä lisää toimenpiteitä vai onko aihe jo ohi? Samaan tapaan kuin GDPR, tämä keskustelu ei ole vielä päätynyt tai hävinnyt. Päinvastoin henkilötietojen käsittely Yhdysvaltalaisilta palveluntarjoajilta on yhä tarkemman tarkastelun kohteena, ja organisaatioita on Suomessa ja muualla Euroopassa varoitettu ja sakotettu useista syistä.
Keskustelussa on myös noussut esiin mahdollisen ”Privacy Shield II” -sopimuksen tarve. On huomionarvoista, että Privacy Shield on edelleen käytössä Yhdysvalloissa, mutta se ei tällä hetkellä tarjoa riittävää suojaa Euroopan ja Yhdysvaltojen välillä. Mahdollinen uusi sopimus on nimeltään Data Privacy Framework (DPF), jossa määritellään tarkemmin tietojen suojaukseen liittyviä asioita. DPF perustuu presidentti Bidenin antamaan määräykseen, mutta tämä herättää huolta siitä, mitä tapahtuu, jos seuraava valittu presidentti kumoaa sopimuksen ja koko prosessi alkaa alusta. Organisaatioiden on kuitenkin huolehdittava tietojen asianmukaisesta suojaamisesta tänäkin aikana. Aiheeseen liittyen on tehty useita tutkintapyyntöjä ja mahdollisia tietojen käsittelykieltoja. Tietojen suojaamisen kannalta on tärkeää tietää, missä tiedot todellisuudessa tallennetaan. Tämän tukena on tietojen kuvauksen päivittäminen (data flow).
Aika ratkaista tietosuojan rakenteettoman tiedon riskit
Rakenteeton tieto ja siihen liittyvät haasteet ovat edelleen keskeisessä roolissa tietosuojatyössä, samoin kuin tietoturva ja suojaukset. Digi- ja väestötietoviraston (DVV) kesäkuun seminaaripäivässä puhuttiin juuri rakenteettoman tiedon riskeistä. Tähän liittyen tarkastellaan verkkolevyjä ja Teams-työtiloja: ovatko ohjeistukset noudatettu, onko vanhaa tietoa jäänyt talteen ja mikä on yleinen suojauksen taso?
Jos rakenteettoman tiedon riskit huolestuttavat sinua, ota yhteyttä! Voimme vastata näihin ja moniin muihin kysymyksiin kartoituspalvelumme avulla. Olemme myös Kuntien Tieran toimittajalistalla, joten voimme tarjota kilpailutusmahdollisuuksia rakenteettoman tiedon konsultointiin.
Tietosuojatyö ei pääse kesälomalle – Autamme sinua myös lomakaudella
Tietosuojatyö ei pysähdy kesälomalla, joten jos tarvitset apua esimerkiksi tietosuojavastaavan poissaolon aikana, ota rohkeasti yhteyttä. Me teemme tiiminä niin tietosuojavastaavan kuin tietosuojavastaavan tukityötä ympäri Suomen koko lomakauden ajan.